整理TensorFlow学习笔记
TensorFlow 安装
pip install tensorflow -i http://mirrors.aliyun.com/pypi/simple/ —trusted-host mirrors.aliyun.com
TensorFlow API
TensorFlow provides multiple APIs.
- The lowest level API—TensorFlow Core— provides you with complete programming control.
We recommend TensorFlow Core for machine learning researchers and others who require fine levels of control over their models. - The higher level APIs are built on top of TensorFlow Core. A high-level API like tf.estimator helps you manage data sets, estimators, training and inference.
TensorBoard
- SCALARS:记录单一变量的,使用 tf.summary.scalar() 收集构建。
- IMAGES:收集的图片数据,当我们使用的数据为图片时(选用)。
- AUDIO:收集的音频数据,当我们使用数据为音频时(选用)。
- GRAPHS:构件图,效果图类似流程图一样,我们可以看到数据的流向,使用 tf.name_scope() 收集构建。
- DISTRIBUTIONS:用于查看变量的分布值,比如 W(Weights)变化的过程中,主要是在 0.5 附近徘徊。
- HISTOGRAMS:用于记录变量的历史值(比如 weights 值,平均值等),并使用折线图的方式展现,使用 tf.summary.histogram() 进行收集构建。
TensorFlow概念
- batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
- iteration:1个iteration等于使用batchsize个样本训练一次;
- epoch:1个epoch等于使用训练集中的全部样本训练一次;
eg:训练集有1000个样本,batchsize=10,那么训练完整个样本集需要100次iteration,1次epoch。
Cross Entropy(差熵损失函数)
Perplexity(困惑度)
信息论中,困惑度是一种评判概率模型或概率分布预测的衡量指标,可用于评价模型好坏。
可分为三种:
1. Perplexity of a probability distribution
2. Perplexity of a probability model
3. Perplexity per word
Activation 激活函数
激活函数其中一个重要的作用是加入非线性因素的,解决线性模型所不能解决的问题。
在激活函数运算后,能够起到特征组合的作用。
激活函数通常有如下一些性质:
- 非线性: 当激活函数是线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。但是,如果激活函数是恒等激活函数的时候(即f(x)=x),就不满足这个性质了,而且如果MLP使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的。
- 可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
- 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
- f(x)≈x: 当激活函数满足这个性质的时候,如果参数的初始化是random的很小的值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要很用心的去设置初始值。
- 输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate.
这些性质,也正是我们使用激活函数的原因。
激活函数比较

- sigmoid 缺点
- 两头过于平坦
- 输出值域不对称(非0均值)
- tanh 缺点:
- 两头依旧过于平坦
- ReLU优缺点:
- 收敛速度比 sigmoid/tanh 更快
- 计算高效简单
- Dead Area 中权重不更新(leaky ReLU 不存在 dead area)
一般现在都直接取 ReLU,然而如果使用 ReLU,一定要小心设置 learning rate,要注意不要让你的网络出现很多 “dead” 神经元,
如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU、random ReLU 或者 Maxout。
另外,现在主流的做法,会多做一步batch normalization,尽可能保证每一层网络的输入具有相同的分布,见Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。
Softmax函数
wiki百科对softmax函数的定义:
softmax is a generalization of
logistic functionthat “squashes”(maps) a K-dimensional vector z of arbitrary real values to a K-dimensional vector σ(z) of real values in the range (0, 1) that add up to 1.
这句话既表明了softmax函数与logistic函数的关系,也同时阐述了softmax函数的本质就是将一个K维的任意实数向量压缩(映射)成另一个K维的实数向量,其中向量中的每个元素取值都介于(0,1)之间。
它在多元分类(Multiclass Classification)和神经网络中也有很多应用。
Softmax 不用于普通的”max”函数,”max”函数只输出最大的那个值,而 Softmax 则确保较小的值也有较小的概率,不会被直接舍弃掉,是一个比较“Soft”的“max”。
更形象的如下图表示: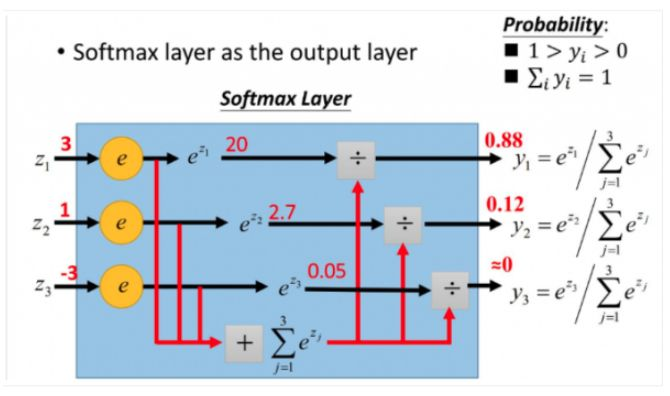
softmax直白来说就是将原来输出是3,1,-3通过softmax函数一作用,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
softmax 可以理解为归一化,
如目前图片分类有100种,那经过 softmax 层的输出就是一个100维的向量。
向量中的第1个值就是当前图片属于第1类的概率值,向量中的第2个值就是当前图片属于第2类的概率值…这100维的向量之和为1.
softmax的输入层和输出层的维度是一样的,如果不一样,就在输入至 softmax 层之前通过一层全连接层。
Dropout层
为输入数据施加Dropout。Dropout将在训练过程中每次更新参数时随机断开一定百分比(p)的输入神经元连接,
Dropout层用于防止过拟合。
Flatten层
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
全连接层
输出全连接层神经元的数量