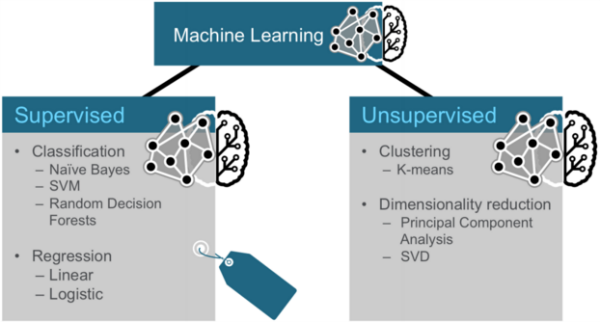
机器学习中监督学习(分类/回归)/非监督学习(聚类/降维)的常算法
机器学习方法论
数据集
- 训练数据(Test Data):用于模型构建
- 验证数据(Validation Data):可选,用于辅助模型构建,可以重复使用。
- 测试数据(Test Data):用于检测模型构建,此数据只在模型检验时使用,用于评估模型的准确率。绝对不允许用于模型构建过程,否则会导致过渡拟合。
监督学习
分类问题
Naive Bayes(朴素贝叶斯)
SVM(支持向量机)
Random Forests(随机森林)
GBM
逻辑回归
回归问题
随机森林
线性回归
Ridge
Lasso
SVR
无监督学习
聚类问题
K最近邻法
降维问题
PCA(主成分分析)
SVD
模型评估
ROC
ROC曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,
ROC曲线称为受试者工作特征曲线 (receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve),
在计算ROC曲线之前,首先要了解一些基本概念。
在二元分类模型的预测结果有四种,以判断人是否有病为例:
真阳性(TP):诊断为有,实际上也有病。
伪阳性(FP):诊断为有,实际却没有病。
真阴性(TN):诊断为没有,实际上也没有病。
伪阴性(FN):诊断为没有,实际却有病。
ROC空间将伪阳性率(FPR)定义为X轴,真阳性率(TPR)定义为Y轴。
TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率,TPR=TPTP+FN 。
FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率,FPR=FPFP+TN。
AUC
AUC(Area Under Curve)是ROC曲线下的面积。
Precision
Recall
F1
问题
如何将数据集划分为测试数据集和训练数据集?
- 像sklearn一样,提供一个将数据集切分成训练集和测试集的函数: 默认是把数据集的75%作为训练集,把数据集的25%作为测试集。
交叉验证(一般取十折交叉验证:10-fold cross validation) k个子集,每个子集均做一次测试集,其余的作为训练集。 交叉验证重复k次,每次选择一个子集作为测试集,并将k次的平均交叉验证识别正确率作为结果。- 训练数据,验证数据(注意区别交叉验证数据集),测试数据(在Coursera上提到) 一般做预测分析时,会将数据分为两大部分。一部分是训练数据,用于构建模型,一部分是测试数据,用于检验模型。
但是,有时候模型的构建过程中也需要检验模型,辅助模型构建,所以会将训练数据在分为两个部分:
- 训练数据;
- 验证数据(Validation Data)。验证数据用于负责模型的构建。典型的例子是用K-Fold Cross Validation裁剪决策树,求出最优叶节点数,防止过渡拟合(Overfitting)。
所以: