Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce的思想是分而治之(任务的分解与结果的汇总)。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算存储提供了底层支持。
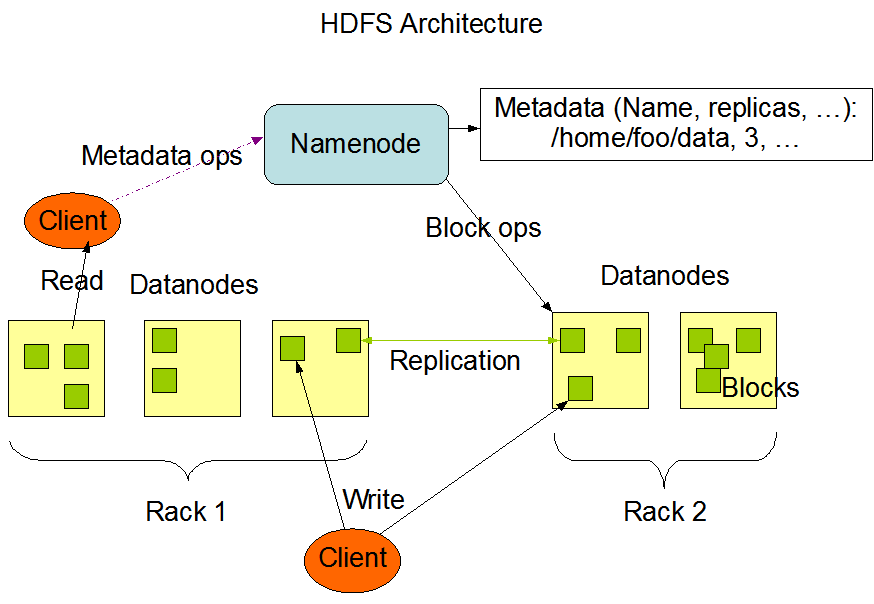
HDFS的基本概念
数据块(block)
HDFS默认的最基本的存储单位是64M的数据块。和普通文件系统相同的是,HDFS中的文件是被分成64M一块的数据块存储的。不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间。
元数据节点(Namenode)
元数据节点用来管理文件系统的命名空间。其将所有的文件和文件夹的元数据保存在一个文件系统树中。这些信息也会在硬盘上保存成以下文件:命名空间镜像(namespace image)及修改日志(edit log)其还保存了一个文件包括哪些数据块,分布在哪些数据节点上。然而这些信息并不存储在硬盘上,而是在系统启动的时候从数据节点收集而成的。
数据节点(datanode)
数据节点是文件系统中真正存储数据的地方。客户端(client)或者元数据信息(namenode)可以向数据节点请求写入或者读出数据块。其周期性的向元数据节点回报其存储的数据块信息。
从元数据节点(secondary namenode)
从元数据节点并不是元数据节点出现问题时候的备用节点,它和元数据节点负责不同的事情。其主要功能就是周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。合并过后的命名空间镜像文件也在从元数据节点保存了一份,以防元数据节点失败的时候,可以恢复。
HDFS读文件原理
//TODO
HDFS写文件原理
//TODO
HDFS文件操作
上传本地文件到hdfs
使用Java实现在HDFS中创建文件夹1
2
3hdfs dfs -rm /user/uadb/etl/geocoding
hdfs dfs -rm /user/uadb/etl/geocoding
hdfs dfs -put /user/uadb/etl/geocoding /user/uadb/etl/
删除hdfs文件
- rm命令:
-rm [-f] [-r|-R] [-skipTrash] <src> ...]
删除hdfs文件夹内所有文件:hdfs dfs -rm -R /user/hive/warehouse/geocodingdb.db/addressnodesgroupbyskeleton/*
删除hdfs文件夹
- rmdir命令:
[-rmdir [--ignore-fail-on-non-empty] <dir> ...],不能删除非空文件夹
hdfs dfs -rmdir /user/hive/warehouse/geocodingdb.db/addressnodesgroupbyskeleton
HDFS相关
为什么HDFS不适合大量小文件
1)在HDFS中,namenode将文件系统中的元数据存储在内存中,因此,HDFS所能存储的文件数量会受到namenode内存的限制。一般来说,每个文件、目录、数据块的存储信息大约占150个字节,根据当前namenode的内存空间的配置,就可以计算出大约能容纳多少个文件了。
2)有一种误解就是,之所以HDFS不适合大量小文件,是因为即使很小的文件也会占用一个块的存储空间。这是错误的,HDFS与其它文件系统不同,小于一个块大小的文件,不会占用一个块的空间。