dolphinscheduler这个dag的任务类型就差flink就都玩个遍了.
简单记录一下,flink word count入门小实验。
Flink on Yarn执行流程
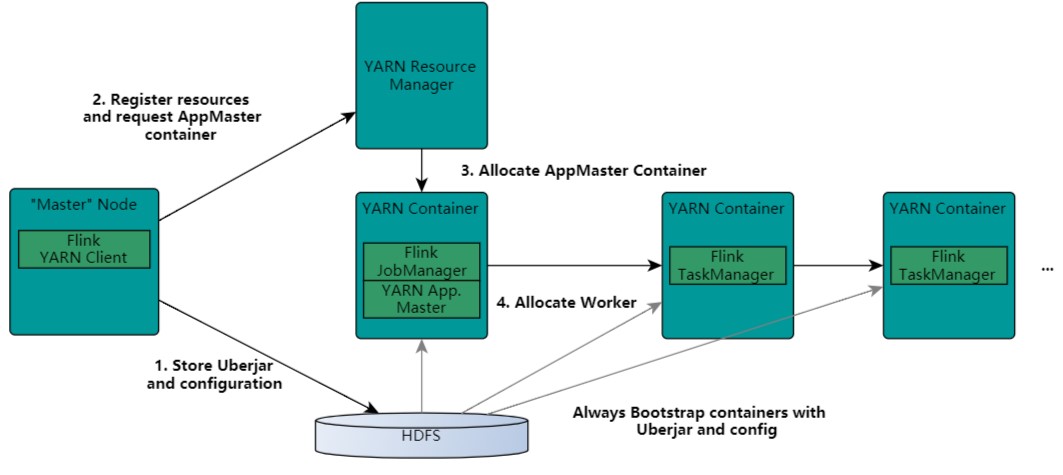
yarn任务提交流程和
spark on yarn类似
不过ui端口,spark是启在driver,flink是启在jobManager
Flink on Yarn 部署模式
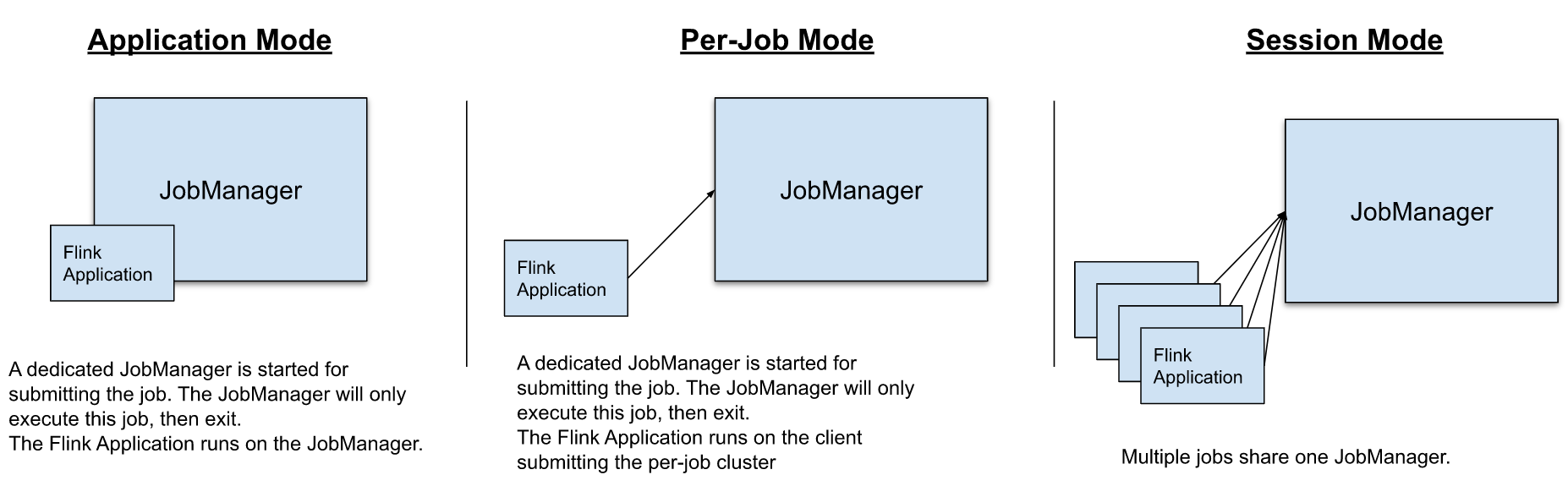
- Application Mode:JobManager独立,flink main()在cluster中执行
- Per-Job Mode:JobManager独立,flink main()在client中执行
- Session Mode:JobManager共享,flink main()在client中执行
数据加工时,由于采用flink定时跑批,租户隔离保证互不影响,所以采用第一种模式;
flink版本
- flink 1.10.2
1.11和1.12的spark on yarn的参数改动有点大,还是保守点用1.10了。
其实是dolphinscheduler目前支持的是1.9…升级flink run的args拼起来太麻烦了-_-
环境变量
1 | export HADOOP_CLASSPATH=`hadoop classpath` |
kerberos初始化
kinit -kt /etc/krb5/$principle.keytab $principle
Flink WordCount
WordCount-batch
1 | flink run -m yarn-cluster \ |
WordCount-streaming
- 在某个服务器192.168.1.6开启socket端口监听:nc -l 9000
- 启动flink streaming任务计算wordcount
1 | flink run \ |
flink jobmanager
1 | Found Web Interface 192.168.1.7:40320 of application 'application_1611216022576_0309'. |
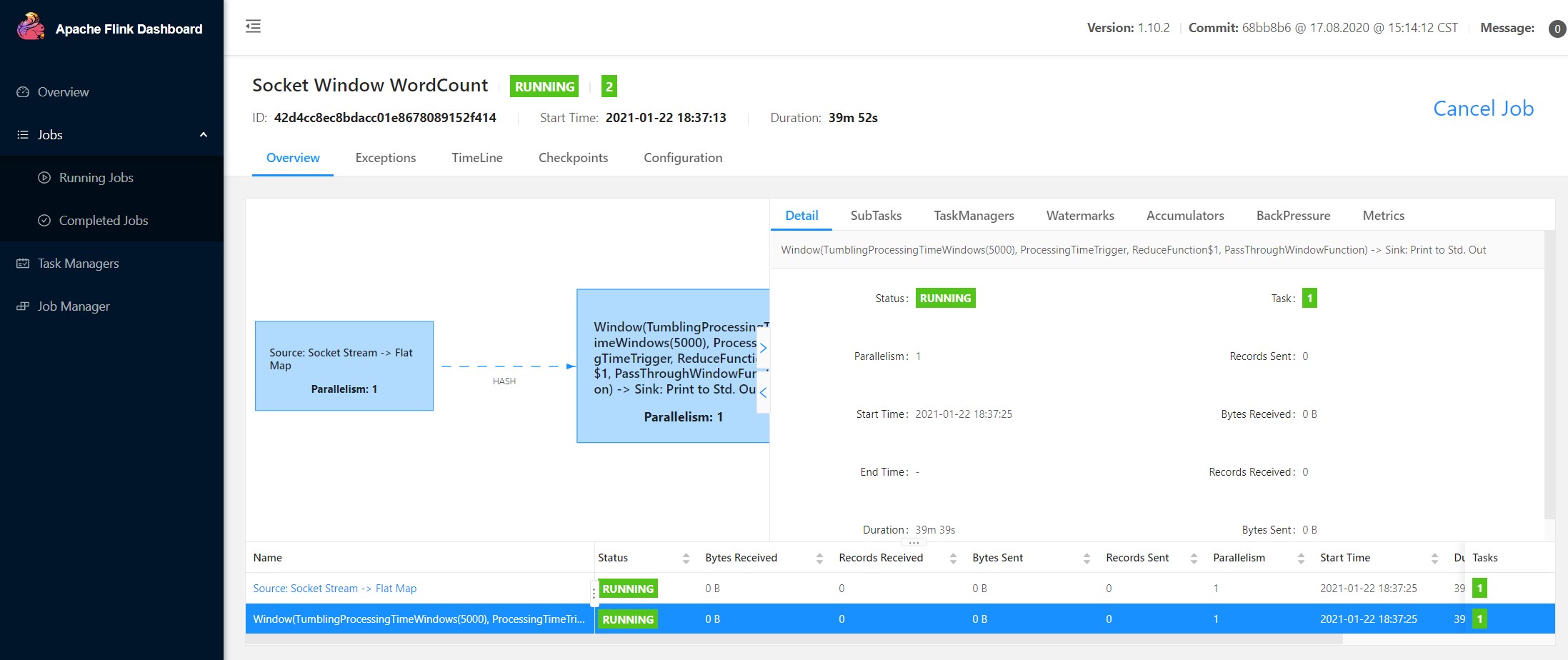
PS 不说流计算的时效性,flink的web ui比spark实在强太多了。