开始正式接触Hadoop,从CDH自动化分布式环境部署延伸的Hadoop生态圈的术语,列举如下:
查看所有术语
Apache Accumulo
基于谷歌 BigTable 设计的分类、分布键值存储。Accumulo 为在 HDFS 上运行的 NoSQL DBMS,支持高效存储和结构化数据检索,包括查询范围。Accumulo 表可用作 MapReduce 作业的输入和输出。Accumulo 功能包括自动负载平衡和分区、数据压缩和细粒度安全标签。
Apache Avro
在网上存储和传输数据的序列化系统。Avro 为 Avro 数据序列(通常称为“Avro 数据文件”)提供丰富的数据结构、紧凑的二级制编码和容器文件的支持。Avro 独立于语言,可使用多个语言绑定,包括 Java、C、C++、Python 和 Ruby。生成或使用文件的 CDH 中的所有组件支持 Avro 数据文件作为文件格式。
Avro 提供与系统(如 Apache Thrift)和协议缓冲类似的功能。
Apache Bigtop
开发封装和 Apache Hadoop 生态系统项目的互操作性测试的项目。
Apache Crunch
用于编写、测试和运行 MapReduce 管道的 Java 库。请参见 Apache Crunch。
Apache Flume
一个分布式、可靠可用的系统,用于高效收集、聚合和移动大量文本或从多个不同源至集中式数据存储的流数据。
Apache Giraph
一个在 Apache Hadoop 上运行的大型、容错的图像处理框架。
Apache Hadoop
一个免费的开源软件框架,支持数据密集型分布应用程序。Apache Hadoop的核心组件为 HDFS 和 MapReduce 和 YARN 处理框架。该术语也用于与 Hadoop 相关的生态系统项目,位于分布式计算和大规模数据处理的基础架构之下。
MapReduce
MapReduce采用”分而治之”的思想,把对大规模数据集的操作,分发给一个主节点管理下的各个分节点共同完成,然后通过整合各个节点的中间结果,得到最终结果。简单地说,MapReduce就是”任务的分解与结果的汇总”。
在Hadoop中,用于执行MapReduce任务的机器角色有两个:一个是JobTracker;另一个是TaskTracker,JobTracker是用于调度工作的,TaskTracker是用于执行工作的。一个Hadoop集群中只有一台JobTracker。
在分布式计算中,MapReduce框架负责处理了并行编程中分布式存储、工作调度、负载均衡、容错均衡、容错处理以及网络通信等复杂问题,把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务,reduce负责把分解后多任务处理的结果汇总起来。
需要注意的是,用MapReduce来处理的数据集(或任务)必须具备这样的特点:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
MapReduce v1 (MRv1)
- MapReduce 作业执行的运行时间框架。它定义两个守护程序:
- JobTracker - 协调运行 MapReduce作业,并提供资源管理和作业生命周期管理。在 YARN 中,这些功能由两个单独组件执行。
- TaskTracker - 运行 MapReduce 作业已拆分的任务。
WordCount流程
- HUE新建输入文件:txt
HUE地址:http://server1.lt.com:8888/filebrowser/;或者在xshell中su hdfs切换用户新建文件:file01.txt,file02.txt
- 查看输入文件 :
hadoop fs -ls /user/uadb/exchange/input/wordCount/ - 查看输入文件内容:
hadoop fs -cat /user/uadb/exchange/input/wordCount/file*.txt
- 上传apreduce程序:jar
- 运行MapReduce程序:
hadoop jar /uadb/wordCount.jar me.demo.hadoop.mapreduce.WordCount /user/uadb/exchange/input/wordCount/ /user/uadb/exchange/output/wordCount
FatJar打包:hadoop jar /uadb/wordCount.jar com.simontuffs.onejar.Boot /user/uadb/exchange/input/wordCount/ /user/uadb/exchange/output/wordCount - 查看执行结果:
hadoop fs -cat /user/uadb/exchange/output/wordCount/*-0000*
YARN
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
YARN最初是为了修复MapReduce实现里的明显不足,并对可伸缩性(支持一万个节点和二十万个内核的集群)、可靠性和集群利用率进行了提升。YARN实现这些需求的方式是,把Job Tracker的两个主要功能(资源管理和作业调度/监控)分成了两个独立的服务程序——全局的资源管理(RM)和针对每个应用的应用 Master(AM),这里说的应用要么是传统意义上的MapReduce任务,要么是任务的有向无环图(DAG)。
运行分布式应用程序的通用体系结构。YARN 指定以下组件:
ResourceManager - 管理计算资源的全局分配至应用程序。
ApplicationMaster - 管理应用程序的生命周期
NodeManager - 启动和监视群集中机器上的计算容器
JobHistory Server - 跟踪已完成的应用程序
主应用程序为群集资源与资源管理器协商 - 按照多个容器的描述,每个应用程序拥有特定的内存限制 - 然后在这些容器中运行应用程序特定的进程。在群集节点上运行的节点管理器监督容器,确保应用程序未使用超出其已分配资源的资源。
MapReduce v2 (MRv2) 作为 YARN 应用程序实施。
Apache HBase
面向列的可伸缩分布式数据存储。它提供实时读/写随机访问 HDFS 托管的大规模数据集的权限。
Hbase Web UI:http://{master}:60010/
Hbase表结构设计
在HBase中,数据是按Column Family来分割的,同一个Column Family下的所有列的数据放在一个文件(为简化下面的描述在此使用文件这个词,在HBase内部使用的是Store)中。
HBase本身的设计目标是 支持稀疏表,而 稀疏表通常会有很多列,但是每一行有值的列又比较少。
如果不使用Column Family的概念,那么有两种设计方案:
1.把所有列的数据放在一个文件中(也就是传统的按行存储)。那么当我们想要访问少数几个列的数据时,需要遍历每一行,读取整个表的数据,这样子是很低效的。
2.把每个列的数据单独分开存在一个文件中(按列存储)。那么当我们想要访问少数几个列的数据时,只需要读取对应的文件,不用读取整个表的数据,读取效率很高。然而,由于稀疏表通常会有很多列,这会导致文件数量特别多,这本身会影响文件系统的效率。
而Column Family的提出就是为了在上面两种方案中做一个折中。HBase中 将一个Column Family中的列存在一起,而不同Column Family的数据则分开。
由于在HBase中Column Family的数量通常很小,同时HBase建议把经常一起访问的比较类似的列放在同一个Column Family中,这样就可以在访问少数几个列时,只读取尽量少的数据。
Hbase性能优化配置
HBase Master 的 Java 堆栈大小(字节)-Master Default Group:377M(默认)>
HBase RegionServer 的 Java 堆栈大小(字节)-RegionServer Default Group :588M(默认)>1024M
HBase 客户端写入缓冲-hbase.client.write.buffer:2M(默认)>
HBaseMaster
HMaster 负责给HRegionServer分配区域,并且负责对集群环境中的HReginServer进行负载均衡,HMaster还负责监控集群环境中的HReginServer的运行状况,如果某一台HReginServer down机,HBaseMaster将会把不可用的HReginServer来提供服务的HLog和表进行重新分配转交给其他HReginServer来提供,HBaseMaster还负责对数据和表进行管理,处理表结构和表中数据的变更,因为在 META 系统表中存储了所有的相关表信息。并且HMaster实现了ZooKeeper的Watcher接口可以和zookeeper集群交互。
HRegionServer
HReginServer负责处理用户的读和写的操作。HReginServer通过与HBaseMaster通信获取自己需要服务的数据表,并向HMaster反馈自己的运行状况。当一个写的请求到来的时候,它首先会写到一个叫做HLog的write-ahead log中。HLog被缓存在内存中,称为Memcache,每一个HStore只能有一个Memcache。当Memcache到达配置的大小以后,将会创建一个MapFile,将其写到磁盘中去。这将减少HReginServer的内存压力。当一起读取的请求到来的时候,HReginServer会先在Memcache中寻找该数据,当找不到的时候,才会去在MapFiles 中寻找。
HBase Client
HBase Client负责寻找提供需求数据的HReginServer。在这个过程中,HBase Client将首先与HMaster通信,找到ROOT区域。这个操作是Client和Master之间仅有的通信操作。一旦ROOT区域被找到以后,Client就可以通过扫描ROOT区域找到相应的META区域去定位实际提供数据的HReginServer。当定位到提供数据的HReginServer以后,Client就可以通过这个HReginServer找到需要的数据了。这些信息将会被Client缓存起来,当下次请求的时候,就不需要走上面的这个流程了。
HBase Service
HBase Thrift Server和HBase REST Server是通过非Java程序对HBase进行访问的一种途径。
Lily HBase Indexer
Lily HBase Indexer provides the ability to quickly and easily search for any content stored in HBase.
It allows you to quickly and easily index HBase rows into Solr, without writing a line of code. It doesn’t require Lily, but originates from years of experience indexing HBase as part of Lily - the Customer Intelligence Data Management Platform from NGDATA.
Lily HBase Indexer drives HBase indexing support in Cloudera Search, the SEP trigger notification mechanism is used inside Lily as well.
Lily HBase NRT Indexer服务,Lily HBase Indexer是一款灵活的、可扩展的、高容错的、事务性的,并且近实时的处理HBase列索引数据的分布式服务软件。它是NGDATA公司开发的Lily系统的一部分,已开放源代码。Lily HBase Indexer使用SolrCloud来存储HBase的索引数据,当HBase执行写入、更新或删除操作时,Indexer通过HBase的replication功能来把这些操作抽象成一系列的Event事件,并用来保证写入Solr中的HBase索引数据的一致性。并且Indexer支持用户自定义的抽取,转换规则来索引HBase列数据。Solr搜索结果会包含用户自定义的columnfamily:qualifier字段结果,这样应用程序就可以直接访问HBase的列数据。而且Indexer索引和搜索不会影响HBase运行的稳定性和HBase数据写入的吞吐量,因为索引和搜索过程是完全分开并且异步的。Lily HBase Indexer在CDH5中运行必须依赖HBase、SolrCloud和Zookeeper服务。
Morphlines
Morphlines是一款开源的,用来减少构建hadoop ETL数据流程时间的应用程序。它可以替代传统的通过MapReduce来抽取、转换、加载数据的过程,提供了一系列的命令工具,
具体可以参见:http://kitesdk.org/docs/0.13.0/kite-morphlines/morphlinesReferenceGuide.html。
对于HBase的其提供了extractHBaseCells命令来读取HBase的列数据。
我们采用Cloudera Manager来管理morphlines.conf文件,使用CM来管理morphlines.conf文件除了上面提到的好处之外,还有一个好处就是当我们需要增加索引列的时候,如果采用本地路径方式将需要重新注册Lily HBase Indexer的配置文件,而采用CM管理的话只需要修改morphlines.conf文件后重启Key-Value HBase Indexer服务即可,CM会自动分发给集群。
HDFS
Hadoop分布式文件系统(Distributed File System)
- Namenode
Namenode 管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。
Namenode结构图课抽象为如图: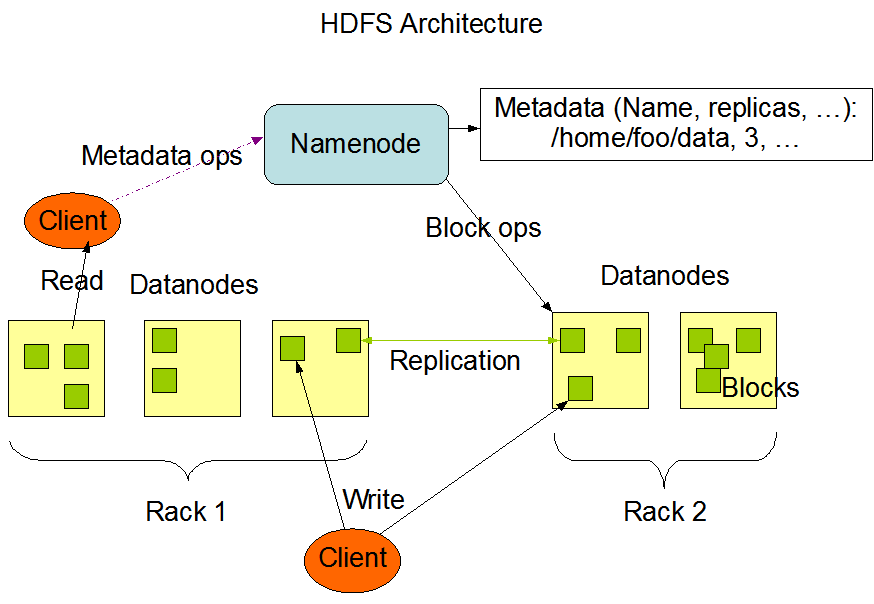
NameNode Web UI:http://master.lt.com:50070/
客户端(client)代表用户与namenode和datanode交互来访问整个文件系统。客户端提供了一些列的文件系统接口,因此我们在编程时,几乎无须知道datanode和namenode,即可完成我们所需要的功能。
- Datanode
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
Apache Solr
Solr是Apache Lucene项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr 4还增加了NoSQL支持,以及基于Zookeeper的分布式扩展功能SolrCloud。
- Solr可用于Hbase的二级索引
Apache Hive
Hadoop 的数据仓库系统,使用诸如 SQL 的语言(称为 HiveQL),有助于实现汇总和 HDFS 中存储的大数据集的分析。
HiveServer
支持通过 Apache Thrift 连接将客户端连接至 Hive 的服务器进程。
HiveServer2
支持通过网络连接将客户端连接至 Hive 的服务器进程。这些客户端可以是本机命令行编辑器或使用 ODBC 或 JDBC 驱动程序的应用程序和工具。
HiveQL
Hadoop 的一种查询语言,使用类似于标准 SQL 的语法,以在 HDFS 上执行 MapReduce 作业。HiveQL 不支持所有的 SQL 功能。不支持事务和物化视图,对索引和查询的支持有限。它支持不属于标准 SQL 的功能,如多表格,包括多表格插入和创建选择的表格。
在内部,编译器将 HiveQL 语句转换为 MapReduce 作业的有向无环图,提交至 Hadoop,以执行。Beeswax 包含在 Hue内,为 HiveQL 查询提供图形化前端。
Apache Mahout
Hadoop 的机器学习库。它是您能够构建克扩展至大型数据集的机器学习库,从而简化了构建智能应用程序的任务。Mahout 支持的主要使用情形包括:
- 建议挖掘 -基于过去偏好标识用户喜好,如在线购物建议。
- 群集 - 类似项目的组;如解决类似主题的文档
- 分类 - 学习现有类别中成员的共同之处,然后使用该信息分类新项目。
- 频繁的项目集挖掘 - 采用一组项目组(如查询会话或购物车中的条目),识别通常一起出现的项目。
Apache Oozie
协调数据接收、存储、转换和分析操作的工作流程和协调服务。
Apache Pig
数据流语言和在 MapReduce 顶部构建的并行执行框架。在内部,编译器将 Pig 语句转换为 MapReduce 作业的有向无环图,提交至 Hadoop,以执行。
Apache Sentry
企业级大数据安全的下一步骤,为存储在 Apache Hadoop 中的数据提供细粒度授权。独立的安全模块,集成开源 SQL 查询引擎 Apache Hive 和 Cloudera Impala,Sentry 提供高级身份验证控制以为企业数据集启用多用户应用程序和跨职能流程。
Apache Spark
分布式计算的一般框架,为迭代和交互式处理提供出色性能。Spark 为 Java、Scala 和 Python 展示用户友好的 API。
Apache Sqoop
在 Hadoop 和外部结构化数据存储(如关系数据库)之间高效批量传输数据的工具。Sqoop 导入表格内容至 HDFS、Apache Hive 和 Apache HBase,并生成允许用户解译表架构的 Java 类。Sqoop 也可以从 Hadoop 存储中提取数据,并将记录从 HDFS 导出至外部结构化数据存储,如关系数据库和企业数据仓库。
Sqoop 有两个版本:Sqoop 和 Sqoop 2。Sqoop 要求客户端安装和配置。Sqoop 2 是基于网络的服务,具有客户命令行界面。拥有 Sqoop 2 连接器,在服务器上配置数据库驱动。
Apache ZooKeeper
维护配置信息、命名并提供分布式同步和组服务的集中式服务。
CDH
Cloudera Apache Hadoop 分布包含核心 Hadoop(HDFS、MapReduce、YARN)以及以下相关项目:Apache Avro、Apache Flume、Fuse-DFS、Apache HBase、Apache Hive、Hue、Cloudera Impala、Apache Mahout、Apache Oozie、Apache Pig、Cloudera Search、Apache Sentry、Apache Spark、Apache Sqoop、Apache Whirr、Apache ZooKeeper、DataFu 和 Kite。
CDH 为免费 100% 开源,并在 Apache 2.0 许可证下许可。CDH 支持多个 Linux 分配。
Cloudera Manager
Cloudera Manager定义
CDH、Cloudera Impala 和 Cloudera Search 的端到瑞管理应用程序。Cloudera Manager 允许管理员轻松有效地协调、监控和管理 Hadoop 群集和 CDH 安装。
Cloudera Manager版本
Cloudera Manager 有两个可用版本:Cloudera Express 和 Cloudera Enterprise。
Cloudera Express
免费下载,包含 CDH,涵盖企业级 Apache Hadoop、Apache HBase、Cloudera Impala、Cloudera Search、Apache Spark 和 Cloudera Manager 分布,提供强大的集群管理功能,如自动部署、集中管理、监控和诊断工具。Cloudera Express 使数据驱动的企业可评估 Apache Hadoop。
Cloudera Management Service
Cloudera Management Service 可作为一组角色实施各种管理功能:
- Activity Monitor - 收集有关 MapReduce 服务运行的活动的信息。默认情况下未添加此角色。
- Host Monitor - 收集有关主机的运行状况和指标信息
- Service Monitor - 收集有关服务的运行状况和指标信息以及 YARN 和 Impala 服务中的活动信息
- Event Server - 聚合 relevant Hadoop 事件并将其用于警报和搜索
- Alert Publisher - 为特定类型的事件生成和提供警报
- Reports Manager - 生成报告,它提供用户、用户组和目录的磁盘使用率的历史视图,用户和 YARN 池的处理活动,以及 HBase 表和命名空间。此角色未在 Cloudera Express 中添加。
Cloudera Manager 将单独管理每个角色,而不是作为 Cloudera Manager Server 的一部分进行管理,可实现可扩展性(例如,在大型部署中,它可用于将监控器角色置于自身的主机上)和隔离。
此外,对于特定版本的 Cloudera Enterprise 许可证,Cloudera Management Service 还为 Cloudera Navigator 提供 Navigator Audit Server 和 Navigator Metadata Server 角色。
Cloudera Impala
可实时查询存储在 HDFS 或 Apache HBase 中数据的服务。它支持相同的元数据和 ODBC 和 JDBC 驱动程序作为 Apache Hive 和基于 Hive 标准查询语言 (HiveQL) 的查询语言。要避免延迟,Impala 规避 MapReduce 通过特殊分布式查询引擎(与商业并行 RDBMS 中的引擎相似)直接访问数据。
Hue
为 CDH 服务构建自定义 GUI 应用程序的服务和包含以下内置应用程序的工具:Apache Pig、Apache HBase 和 Sqoop 2 shell,Apache Pig 编辑器、Beeswax Hive UI,Cloudera Impala 查询编辑器,Solr 搜索应用程序Hive 元存储管理器,Oozie 应用程序编辑器、调度程序和提交者,Apache HBase 浏览器,Sqoop 2 应用程序,HDFS 文件管理器和 MapReduce 和 YARN 作业浏览器。
主页:http://master.lt.com:8888/
MapReduce任务查看:http://192.168.1.100:8888/jobbrowser/
Hbase主页:http://192.168.1.100:8888/hbase
Hue Hbase文档
Hive主页:http://192.168.1.100:8888/beeswax/
问题记录
- Hue-Hbase表中文字段插入和编辑问题